A gépi tanulás, a tanuló algoritmusok és a mesterséges intelligencia a pénzügyi területen is a mindennapok részévé válik. Ráadásul mivel számos, hosszú távra visszanyuló adat áll rendelkezésre, így a pénzügyekben kifejezetten jól alkalmazható az adatokon alapuló tanulás.
A gépi tanulás, a tanuló algoritmusok és a mesterséges intelligencia a pénzügyi területen is a mindennapok részévé válik. Ráadásul mivel számos, hosszú távra visszanyuló adat áll rendelkezésre, így a pénzügyekben kifejezetten jól alkalmazható az adatokon alapuló tanulás.
Korábban több bejegyzésben is foglalkoztunk a prediktív analitikai módszerek vállalati pénzügyek területén történő hasznosítási lehetőségeivel és ennek során néhány példát is bemutattunk (pl. csődvalószínűség mérése/előrejelzése vagy várható költségek előrejelzése), elsősorban a regressziós technikákra alapozva.
A jelen bejegyzésben - valamint a tervek szerint még további 1-2 bejegyzésben - a tanuló algoritmusokon alapuló prediktív analitikai példákkal foglalkozunk. A neurális hálózatokat, illetve azok tanításához használt ún. gradiens („gradient descent”) módszert, valamint a genetikus algoritmusokat fogjuk ugyanazon a példán - csődvalószínűség modellezése - keresztül bemutatni.
 Tanuló algoritmusok, gépi tanulás
Tanuló algoritmusok, gépi tanulás
A gépi tanulás olyan rendszereket/algoritmusokat jelent, amelyek önállóan tanulni képesek, azaz tapasztalatokból tudást generálnak. A rendszer a minták, példa adatok („training set”) alapján képes, alapvetően iteratív tanulási módszerrel szabályszerűségeket, szabályokat felismerni és meghatározni.
Neurális hálók
A neurális hálózatok a gépi tanulásban gyakran alkalmazott olyan matematikai struktúrák, amelyek az idegrendszer működésének elvét másolva tanulnak. Gyakorlatilag egy gráf alapú modell, ahol a gráfok csúcspontjaiban levő mesterséges neuronok küldenek egymásnak jeleket nemlineáris aktivációs függvényeken keresztül. A gráfok csúcspontjait összekötő élek pedig olyan súly tényezők, amelyek azt szabályozzák, hogy az egyes neuronok által küldött jelek milyen súllyal kerülnek figyelembe vételre a következő rétegben.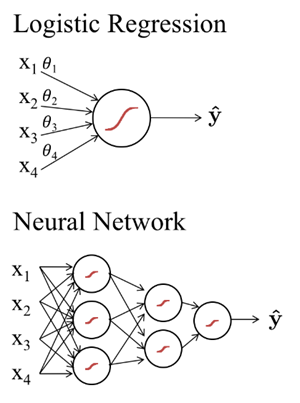
A neurális háló ugyanis egy „rétegzett” struktúra, ahol a bemeneti réteg és kimeneti réteg között akár több rejtett réteg is lehet. Ezekben a rétegekben a mesterségek neuronok jelfeldolgozást és azok továbbítását végzik. A neurális hálózatok tanítása során a rétegeket összekötő súlyokat módosítjuk iteratív módon, grádiens módszerrel*, de a rétegek és neuronok száma, valamint az aktivációs függvény formájának megválasztásával is lehet a tanulási képességet befolyásolni.
A jelen bejegyzésben egy nagyon egyszerű neurális hálóval fogjuk megoldani a feladatot, ami valójában egyetlen neuronból áll, így klasszikus értelemben nem is tekinthető hálózatnak. A neuron a bemenő inputok – vállalkozások pénzügyi mutatói – alapján egy sigmoid függvénnyel fog becslést adni a csődvalószínűségre, vagyis mekkora eséllyel megy csődbe az adott vállalkozás.
Ez tulajdonképpen egy „egyszerű” logisztikus regressziós probléma, azzal a különbséggel, hogy itt nem hagyományos módszerrel próbáljuk a legjobban illeszkedő logisztikus regressziós egyenlet paramétereit meghatározni (ld. korábbi bejegyzés), hanem a „gradient descent” módszerrel.
* a gradiens a függvények deriválásának általánosítása többváltozós függvényekre. Egy skalármező gradiensét a parciális deriváltak vektoraként definiálják.
Szeretnél a prediktív analitikai módszerekről, modern datanalytics eszköztárról és az adatalapú üzleti döntéstámogatásról többet tudni?
Adatvezérelt üzleti döntések képzés
by SonicData
Genetikus algoritmus
A genetikus algoritmus egy speciális megközelítése bizonyos feladatok megoldásának: az alapját az evolúció képezi, mivel „evolúciós” technikákkal keressük az optimális megoldást vagy egy adott tulajdonságú elemet.
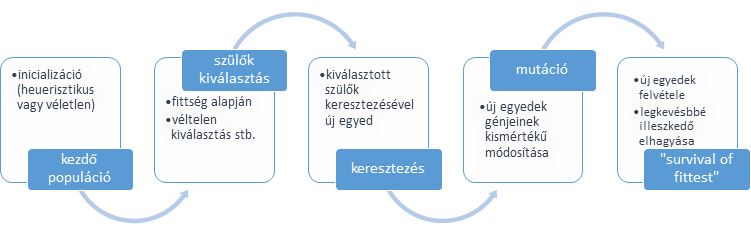
Egy kiinduló populáció (potenciális megoldási lehetőségek halmaza) képezi a keresési teret, amely populáció elemeit keresztezni és mutálni lehet, vagyis új egyedek hozhatók létre. Amennyiben ezek az új egyedek (vagyis potenciális megoldások) egy tanuló adathalmazon vizsgálva jobb megoldást adnak – ún. fittness vagy célfüggvény alapján közelebb vannak a keresett megoldáshoz – akkor kiszorítják a rosszabb megoldást jelentő egyedeket a populációból. A keresés mindaddig folyik, amíg valamilyen előre definiált leállási feltétel (pl. iterációk száma vagy valamilyen illeszkedés / fittness érték elérése) nem teljesül.
A megoldandó feladat – csődvalószínűség modellezése
A bejegyzésben szereplő példában 3 pénzügyi mutató, mint bemeneti paraméterek súlyozott értéke alapján próbáljuk meghatározni, hogy mekkora valószínűséggel megy csődbe az adott vállalkozás. A vizsgálatot - akárcsak a korábbi példában a - likviditás, saját tőke jövedelmezősége (ROE) és eladósodottság (debt/ebitda) mutatók alapján végezzük.
A kimeneti függvényünk egy sigmoid aktivációs függvény, vagyis
σ(z) = 1 / (1 + exp(-z))
ahol z = w1 x [LIKV] + w2 x [ROE] + w3 x [DEBT-TO-EBITDA]
A feladat megtalálni azokat a W (w1 ; w2 ; w3) értékeket, amelyekkel a legjobb becslést kapjuk, vagyis a tanuló adathalmaz tényleges kimeneti értékeit – Y: csőd vs. „túlélés”, vagy 1/0 – a legjobban közelíti az aktivációs függvényünk (σ) eredménye.
Fontos fogalom az ún. költségfüggvény (J), amely a tényleges és kapott kimenet közötti különbség alapján méri a modell (megoldás) „jóságát”. Az optimalizálás során ezt a függvényt minimalizáljuk: a tanuló algoritmus a költségek (az eltérések) csökkentését végzi lépésről lépésre.
Csődvalószínűség becslés gradiens módszerrel
A „gradient descent” egy iteratív optimalizálási algoritmus, amely az adott függvény minimumának a megtalálását végzi. A módszer lényege, hogy egy kezdeti, feltételezett megoldásból kiindulva, iteratív módon, több lépésben a függvény gradiensével arányos, de ellenkező előjelű módosításokat végzünk a megoldást leíró attribútum értékeken, vagyis W (w1 ; w2 ; w3) vektoron. Az arányos módosítás azt jelenti, hogy a hibát nem teljes mértékben vesszük figyelembe, hanem az ún. tanulási ráta alapján (amelynek értéke jellemzően 1% alatti, de nagyságrendileg is változhat).
Az algoritmus előre meghatározott számú vagy valamilyen küszöbtől/feltételtől függő számú lépésben a költségfüggvény minimalizálásra törekszik. Ehhez használja a gradienst, amely tulajdonképpen a költségfüggvény parciális deriváltja.
Mivel logisztikus regressziós problémáról van szó, ezért a költségfüggvény a likelihood függvény logaritmusa, vagyis az ún. log-likelihood függvény (pontosabban annak a mínusz egyszerese):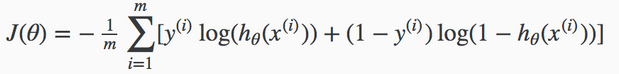
deriváltja: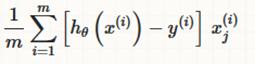
A rövid elvi/matematikai alapok után, tekintsük át, hogy milyen előkészületek szükségesek még a gépi tanulásnál? Nagyon fontos kiemelni, hogy a gyakorlatban az alábbi lépések nélkül a tanuló algoritmusok sokszor nem a megfelelő eredményre vezetnek, vagy csak nagyon lassan konvergálnak az optimális megoldás felé.
Adatok előkészítése:
- feature scaling vagy feature normalization: min-max módszerrel vagy z-score módszerrel a bementi adatok nagyságrendjének közel azonosra alakítása
- „sample balancing”: a minta kiegyensúlyozása, vagyis minden osztályból kb. azonos arányban legyenek elemek a tanuló mintában, de legalábbis ne legyenek jelentősen felülsúlyozva bizonyos típusú minták (konkrétan jelen esetben kb. 50-50% legyen a csődbe ment és túlélő cégek aránya)
Hiperparaméter finomhangolás:
A hiperparaméterek a tanulási algoritmus működését, „ütemét” befolyásoló paraméterek, mint például az iterációk száma vagy a tanulási ráta (ez utóbbi, azt jelenti hogy a hibákból milyen mértékben tanul a rendszer). Ezek finomhangolása során tulajdonképpen azokat a hiperparamétereket keressük, amelyekkel a tanuló algoritmusunk a legjobb eredményre vezet. Többféle technika létezik a manuális finomhangolástól kezdve, azt ezt automatizáló ún. grid search technikán át egészen az evolúciós algoritmusokig… vagyis ez utóbbi esetben már a tanuló algoritmus hiperparamétereit is egy tanuló algoritmus keresi.
A bejegyzésben szereplő példában manuális finomhangolást végeztünk, vagyis eleinte random módon, majd az eredményeket látva tudatosan változtattuk a iterációk számát és a tanulási rátát.
És akkor nézzük az algoritmust, amivel a tanítást végeztük (a teljes algoritmust itt most nem mutatjuk be csak a legfőbb lépéseket)…
- lépés – adatok beolvasása (tanuló és teszt adathalmaz)
df = read.table("defaultLogReg.csv", header = TRUE, sep = ";", dec = ",")
//2-3-4 oszlopokban a likviditás, ROE és debt-to-ebitda mutatók; 1 oszlopban a kimeneti érték
X <- df[, 2:4]
y <- df[, 1]
dfTest = read.table("defaultLogReg_test.csv", header = TRUE, sep = ";", dec = ",")
XTest <- dfTest[, 2:4]
yTest <- dfTest[, 1]
- lépés – kiegyensúlyozott minta vétele
A tanulós adathalmazban az 1000 db mintából 261 olyan, amikor a vállalkozás csődbe ment. Azért, hogy a minta kiegyensúlyozott legyen, ezt a 261 adatot, illetve tovább 250 darabos mintát veszünk azon vállalkozás adathalmazából, amelyek nem mentek csődbe.
dfOK <- df[df$csod == 0,]
dfOK <- dfOK[sample(1:250),]
dfSample <- rbind(dfOK, df[df$csod == 1,])
dfSample <- dfSample[sample(1:nrow(dfSample)),]
- lépés – a tanító adathalmaz bementi értékeinek arányosítása (min-max scaling)
dfSampleScaled[, 2] <- scaleVector(dfSample[, 2], minMax = minMaxing)
dfSampleScaled[, 3] <- scaleVector(dfSample[, 3], minMax = minMaxing)
dfSampleScaled[, 4] <- scaleVector(dfSample[, 4], minMax = minMaxing)
// feature scaling, min-max:
scaledVector <- (dfSample – min(dfSample)) / (max(dfSample)- min(dfSample))
X_mod <- dfSampleScaled[, 2:4]
y_mod <- dfSampleScaled[, 1]
- lépés – logisztikus regressziós egyenlet béta együtthatók meghatározása: gradient descent tanuló algoritmus futtatása különböző hiperparaméter kombinációk mellett
A logRegGradientLearning() függvény egy saját fejlesztés, nem beépített függvény, ami a sztenderd „gradient descent” optimalizálást valósítja meg: ld. az előbb a negatív log-likelihood függvény deriváltjának leképezése és azzal, mint grádienssel végrehajtott módosítások több iteratív lépésben.
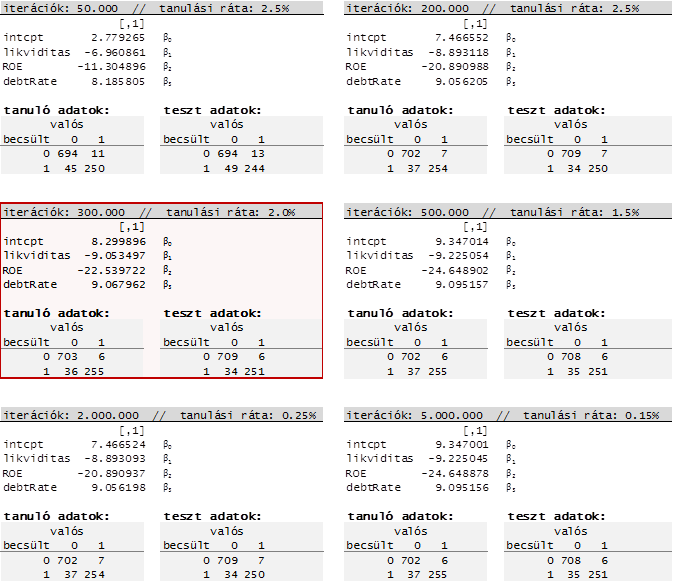
A bemeneti adatok az normalizált X értékek (X_mod), illetve kipróbáltunk több hiperparaméter kombinációt is, a legjobb eredményt akkor kaptuk, amikor 300.000 iterációs lépést hajtottunk végre és a tanulási ráta 2.0% volt.
BH <- logRegGradientLearning(X_mod, y_mod, 300000, 0.02, FALSE)
- lépés – a megtanult béta koefficienseinek a behelyettesítésével előrejelzést készítünk:
Mivel a tanítást min-max módszerrrel arányosított adatokon végeztük el, ezért a logisztikus regressziós számítást is az ellenőrzés során „min-max” arányosított adatokkal kell végezni! A predictLogReg() a σ(z) függvényt képezi le, az X mátrix a minta magyarázó változót tartalmazza, a BH vektor a béta koefficienseket. A modell előrejelző képességét a tanuló adathalmazon is vizsgáljuk és a teszt adathalmazon is
prediction <- predictLogReg(X, BH, y, scaleFeatures = minmax)
table(prediction[, 2], prediction[, 3], dnn = list('becsült','valós'))
prediction2 <- predictLogReg(XTest, BH, yTest, scaleFeatures = scaleParam)
table(prediction2[, 2], prediction2[, 3], dnn = list('becsült','valós'))
A beépített table() függvény egy kontingencia táblázatot generál, amivel ellenőrizzük a kapott eredmények helyességét: mekkora a becslési hiba a tényleges értékekhez képest vagyis a becsült és tényleges értékek hogyan viszonyulnak egymáshoz. Ennek az összefoglalása található az alábbi táblában (a 300.000 lépés esetén 2% tanulási ráta mellett a hibás előrejelzés a túlélő cégek esetében 4.9%, a csődbe menő cégek esetében 2.3%, az átlagos hiba 4.2%)
Csődvalószínűség becslés genetikus algoritmussal
A kapott logit regressziós egyenletünk ß paramétereinek becslését elvégezhetjük genetikus algoritmussal is. Ehhez szintén az R-t használjuk, illetve ahhoz letölthető GA könyvtárat, amely a genetikus algoritmust valósítja meg.... így már csak annak a paraméterezésével kell foglalkoznunk:
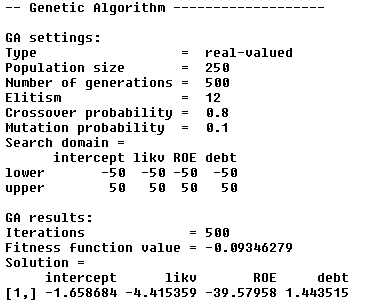
- hiperparaméterek megadása: 250 egyedből álló populáción és 500 iterációval hajtjuk végre az optimalizálást, ahol a ß paraméterek alsó/felső értéke legfeljebb -50/50 (a populáció kiválasztott tagjai között a keresztezés esélye 80%, a mutáció mértéke max. 10% - a ezek a GA algoritmus default értékei az R-ban, ezen nem változtattunk; ileltve az elitizmus mértéke is 5% dafault értéken maradt à a legjobb 5% mindig átkerül a következő populációba)
- optimalizálandó fittness (költség) függvény megadása: jelent esetben ez a LogLike() függvény, vagyis a korábban is hivatkozott log-likelihood
- lépés – GA kódkönyvtár behivatkozása és tanuló adatok beolvasása
library(GA)
df = read.table("defaultLogReg.csv", header = TRUE, sep = ";", dec = ",")
- lépés – genetikus algoritmus futtatása
ga.LOG <- ga(type='real-valued', lower=c(-50,-50, -50, -50), upper = c(50, 50, 50, 50),
popSize=250, maxiter=500, names=c('intercept', 'likv', 'ROE', 'debt'),
keepBest=T, fitness = function(b) -LogLike(df, b[1],b[2], b[3], b[4]))
- lépés – kapott eredmény összefoglalása, logit regressziós ß paraméterek (ld. „Solution”)
summary(ga.LOG)
- lépés – kapott eredmény vizsgálata
prediction <- predictLogReg(X, t(ga.LOG@solution), y, scaleFeatures = 0)
table(prediction[, 2], prediction[, 3], dnn = list('becsült','valós'))
prediction2 <- predictLogReg(XTest, t(ga.LOG@solution), yTest, scaleFeatures = 0)
table(prediction2[, 2], prediction2[, 3], dnn = list('becsült','valós'))

Vagyis a hibás előrejelzés a túlélő cégek esetében 2.6%, a csődbe menő cégek esetében 6.9%, az átlagos hiba 3.7%, ami kicsivel jobb, mint a grádiens módszer esetében (de nem jelentős a különbség)
Csődvalószínűség becslés - GLM
Végezetül szintén R-ban, a beépített "hagyományos" GLM (generalized linear model) modellel is készítettünk egy becslést:
logitMod <- glm(formula = csod ~ ., family = binomial, data = df)
summary(logitMod)

Látható, hogy itt a szinte teljes mértékben a genetikus algoritmussal kapott regressziós koefficiensek köszönnek vissza, így a modell tesztelése is hasonló hiba arányokat mutatott, mint amit az előbbi részben írtunk.
A bejegyzés második részében továbblépünk majd az egy neuronos modell felől egy több neuronból álló, 3 rétegű hálózat irányába...